分多少个库和分多少张表,提前确定好,避免后期变化引起再平衡(rebalance)【迁移或重建】的麻烦,但是由于前期的量还没有达到,可以复用机器来减少开支,根据量的发展情况再独立出来。
迁移:数据迁移,比如schema迁移和表迁移,程序不需要改动或很少改动,DBA进行数据迁移即可。
重建:数据需要重新清理入库,否则会出现找不到数据(分库或分表的数量变了,原路由逻辑不兼容)。解决找不到数据的问题,可以考虑分库分表键冗余分库分表信息,定点查询,这样会出现数据倾斜(有的表数据多,有的表数据少)。
比如,库分4个,表分4个,最多4*4=16个分表
迁移
初期规划2个节点:
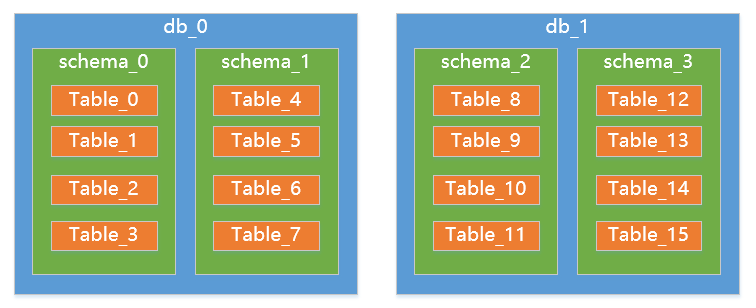
进一步扩展到4个节点(schema迁移):
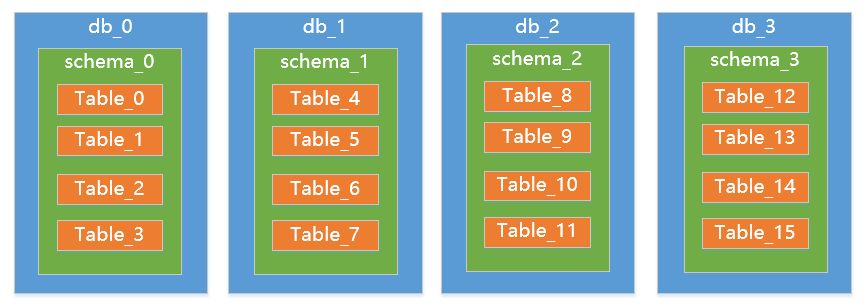
再一步扩展到8个节点(表迁移):
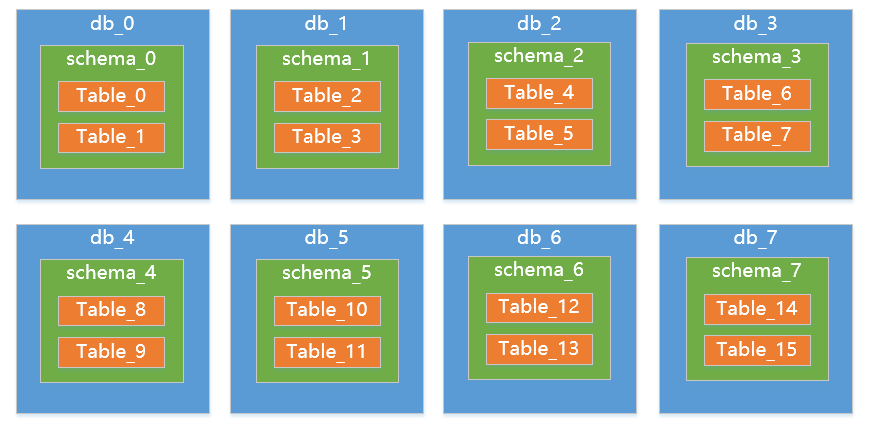
最后扩展到16个节点(表迁移):

以上扩展(2^n)都只涉及到迁移,不需要重建。
重建
如果还得扩展,可以考虑再分库或分表。
比如:
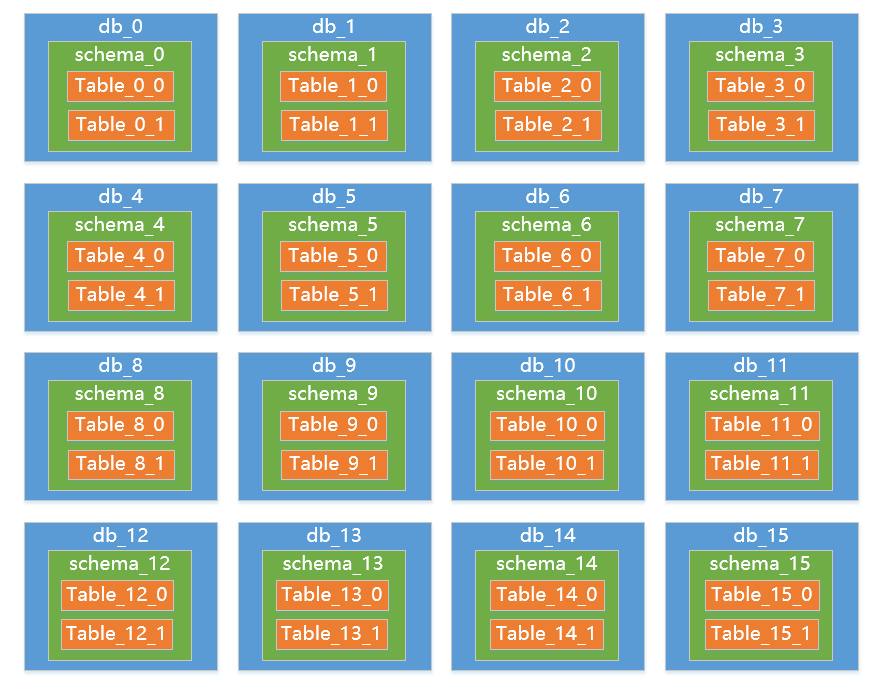
还可能继续扩展加库
由于原表里面有数据,再分表,里面的数据如何处理呢?
这样就需要重建了。
还有一个方案可以考虑,数据库自身的分表技术,对应用是完全透明的。
在线库和历史库
在线库处理联机交易的插入和基于分库分表键的查询/删除/更新。定期清理在线库数据。
后线库处理批量查询。